
Don’t overengineer your agents
We jumped on the train of building a multi-agent systems capable of meeting a wide array of use cases. It was a mistake.
Early on, we built a multi-agent system with managers, workers, and complex orchestration. On paper it looked elegant, but in reality, it took forever and barely worked.
Overengineering is the fastest way to stall momentum. The truth is, you can cover 80% of use cases with simpler patterns. When trying to show value from your AI initiatives, quick wins are key and delays are a death sentence.
We recommend an Occam’s razor approach to building agents - only add complexity when you absolutely have to. And use your evals as a guide. Here’s the ladder we recommend climbing when building your AI agents —and why you should only move up when the pain demands it.
The Agent Architecture Ladder
We think of agent architectures as a ladder. Each rung adds new abilities—but also new overhead. You should only climb when the pain of staying put is bigger than the cost of moving up.
Below is a walk through of the ladder step by step, starting with the simplest setup (a single model with tools) and working up to full-blown multi-agent systems. Along the way, we’ll ground it in two concrete examples:
Customer support bot → answering customer requests with product knowledge and helping by taking basic actions on user accounts.
Data analysis agent → helping conduct data analyses by running SQL queries, generating plots, and writing summaries.
These examples will give you a feel for what each architecture looks like in practice—so you can decide how far up the ladder your team actually needs to climb.
1. Single Agent + Tools
What it is: One model, hooked up to a few tools (search, DB, calculator).
How it works: The agent handles requests directly and hands off to a tool when the task requires data or computation it can’t do alone
Good for: Fast baselines, simple retrieval, lightweight automation.
Industry note: In medical exam benchmarks, single-agent setups solved a large share of questions without any orchestration. Complexity only improved edge cases.
Examples
Customer support: Model + knowledge base = resolves the bulk of inbound questions.
Data analysis: Model + SQL executor = instant answers to straightforward queries.
👉 Start here. Ship a baseline. Don’t move on until you’ve nailed this step.

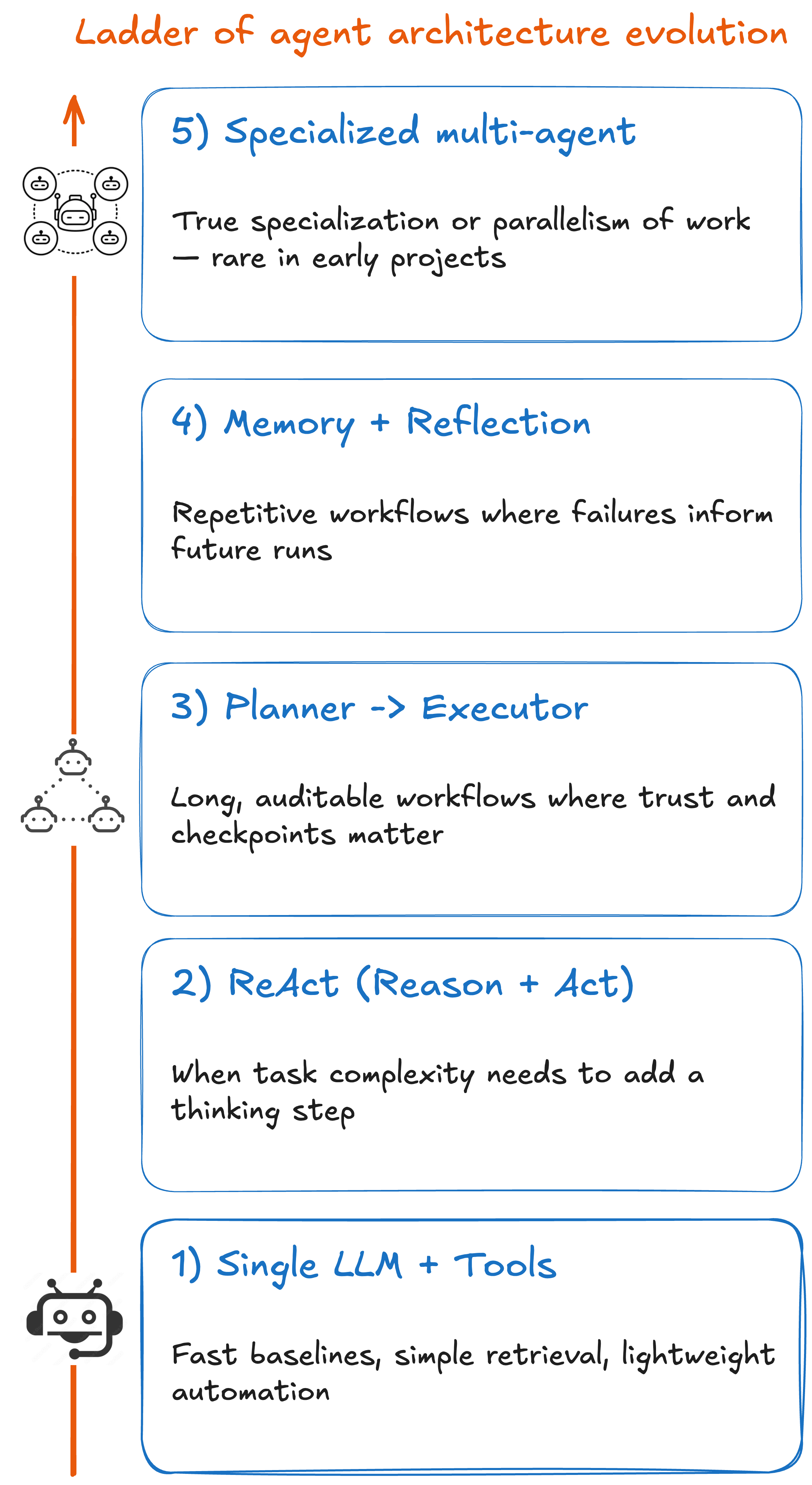
2. ReAct (Reason + Act)
What it is: The model alternates between reasoning and tool use.
Good for: When task complexity needs to add a thinking step
How it works: The agent “thinks” through the problem, calls a tool, then revises its reasoning before the next step
Industry Note: On benchmarks like HotpotQA and WebShop, ReAct consistently outperformed chain-of-thought or single tool calls by interleaving steps.
Customer support: “Where’s my order?” → KB lookup → account status check → final answer.
Data analysis: “Graph churn over 6 months and highlight anomalies.” → SQL query → plot → summary.
👉 Reach for ReAct when you notice tool-hopping or reasoning becoming the bottleneck.
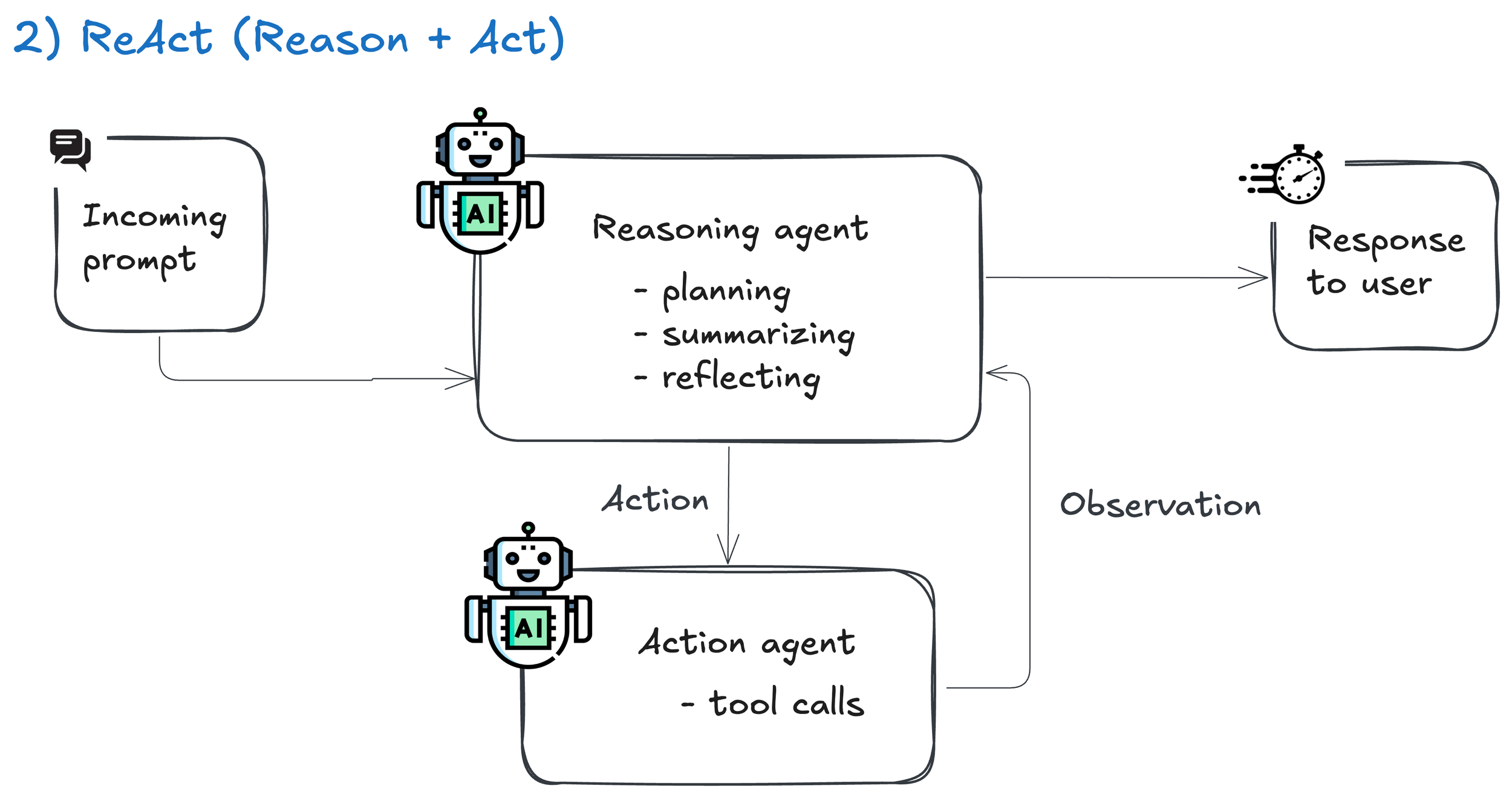
3. Planner → Executor
What it is: The agent makes a plan first, then executes step by step.
How it works: One step generates a clear plan of actions; the next executes each step in sequence, with checkpoints and retries
Good for: Long, auditable workflows where trust and checkpoints matter.
Industry Note: The Plan-and-Act framework hit ~54% success on WebArena-Lite (state of the art), beating simpler baselines by separating planning from execution.
Customer support: Resetting a password → verify identity → reset → confirm → update CRM.
Data analysis: Cohort analysis → define metric → run queries → compile plots → write narrative.
👉 Use this when you need clarity, retries, and logs—not just answers.
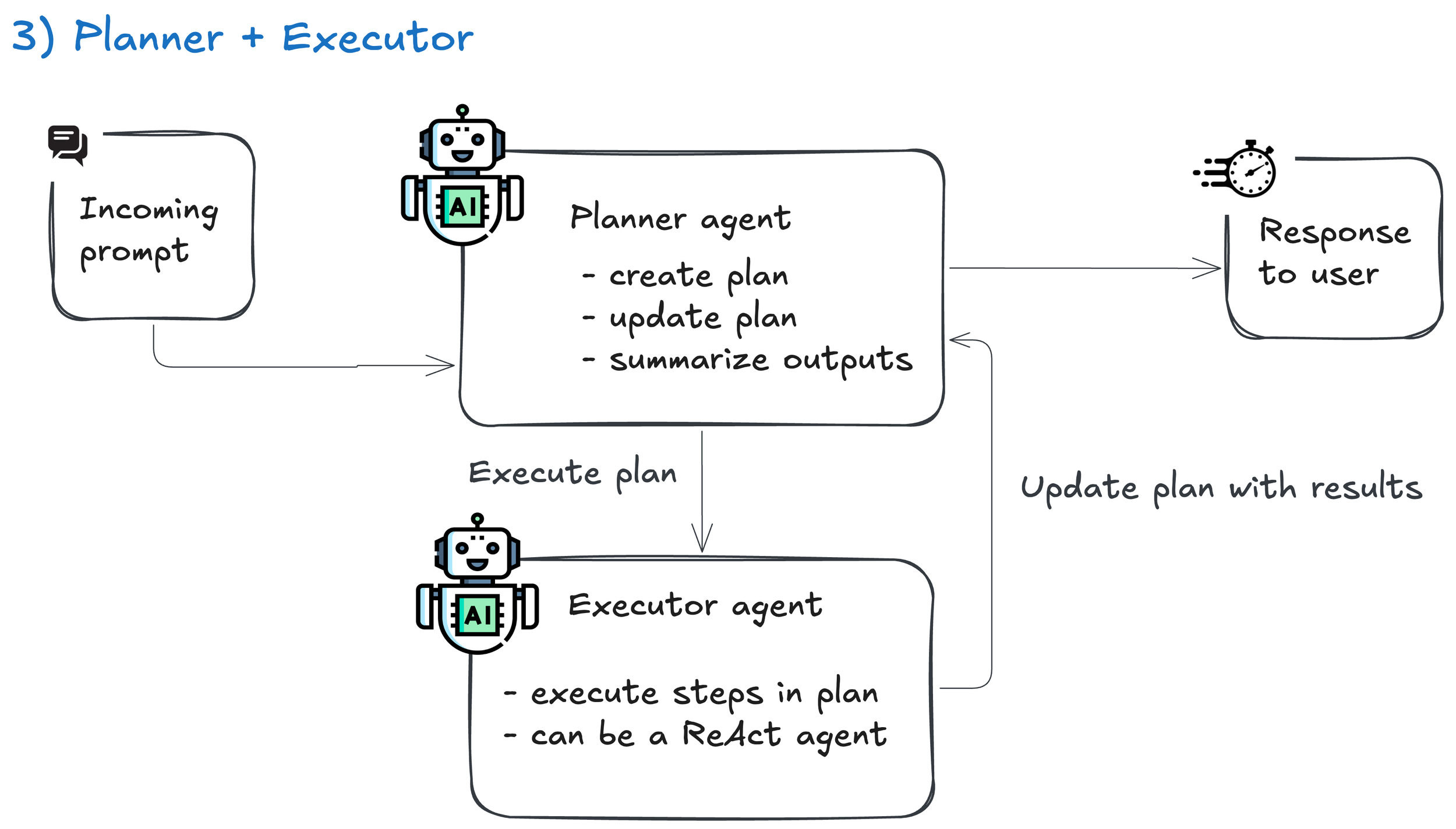
4. Memory + Reflection
What it is: Agent critiques its own output, stores lessons, improves over time.
How it works: After each run, the model reviews its performance, stores insights in memory, and applies them to future attempts
Good for: Repetitive workflows (daily, weekly, etc) where failures inform future runs
Industry note: In Reflective Memory Management (2025), adding reflection on past dialogues improved accuracy by more than 10% on the LongMemEval benchmark vs agents without that mechanism
Customer support: Ticket bot that remembers, “refund questions → escalate.”
Data analysis: Weekly KPI reports that compare trends week over week.
👉 Use this for repetitive jobs like weekly reports where memory improvements matter
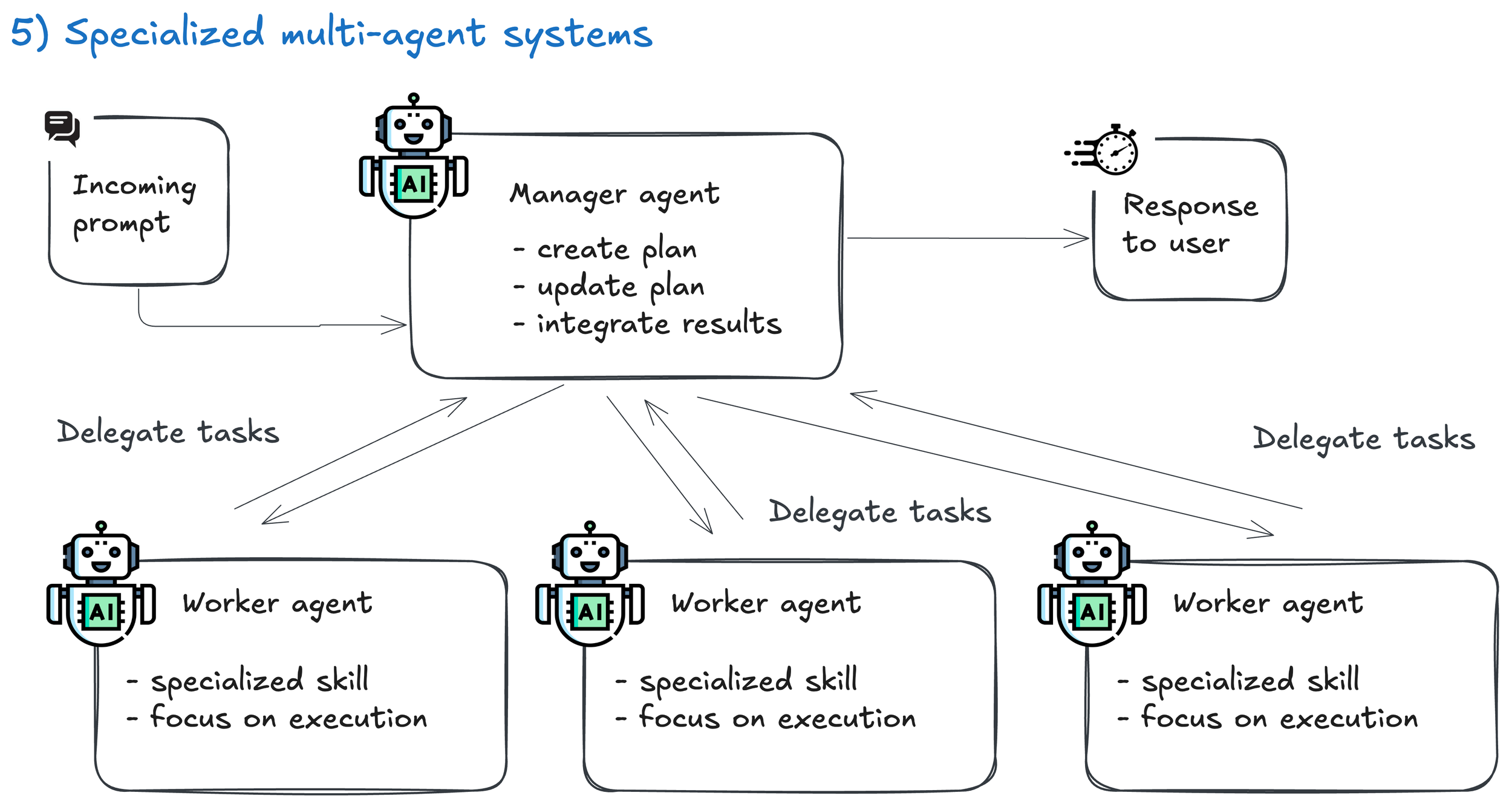
5. Specialized multi-agent systems
What it is: Manager agent delegates to worker agents (SQL, plotting, reviewer, etc.).
How it works: A “manager” agent decomposes the task and delegates to worker agents (e.g., SQL, plotting, reviewer), then integrates their results
Good for: True specialization or parallelism of work —rare in early projects.
Industry Note: Optima showed ~2.8× performance gains, but only on heavy communication tasks—and with measurable coordination costs.
Customer support: Splitting empathy, KB, and supervisor agents. Usually unnecessary unless scale demands it.
Data analysis: SQL agent + visualization agent + narrator agent. Adds complexity, not always value.
👉 Think of this as hiring a team - don’t hire a one when a good builder can do the job.
Final thoughts
Here are some final thoughts as your team starts building your agentic applications, whether you’re building a LangGraph backend or an n8n workflow.
Multi-agent systems incur taxes. You pay it in tokens, in engineering hours and in maintenance. Have conviction that the tax is worth paying before you spend countless product and engineering hours designing and implementing a complex agent system. Remember, each subsequent foundation model also gets better at reasoning and planning, so be careful that your complex system doesn’t become obsolete with the next version of GPT!
Evals are essential to track progress. To navigate the ladder, you need data to show where the agent is improving and where to prioritize which dynamics to improve. Start with a set of baseline evals, highlighting the key aspects that your agent must get right. Identify which aspects you want to improve on the most, make iterative improvements to your agent architecture, and evaluate your progress.